 Universal Dependencies
Universal Dependencies
Universal Dependencies (UD) is a framework for consistent annotation of grammar (parts of speech, morphological features, and syntactic dependencies) across different human languages. UD is an open community effort with over 600 contributors producing over 200 treebanks in over 150 languages. If you are new to UD, you should start by reading the first part of the Short Introduction and then browsing the annotation guidelines.
💡 Understanding UD |
🔍 Using UD |
🔨 Contributing to UD |
|---|---|---|
| Short introduction to UD (history) | Query UD treebanks online | How to contribute to UD |
| Annotation guidelines (changes) UPOS tags ▪ feats ▪ deprels ▪ CoNLL-U format |
Download UD treebanks: all releases ☞ Release 2.18 (May 15, 2026) |
UD mailing list |
| Guidelines issue tracker | ||
| Tutorials and events | Tools for working with UD | |
🚀 Projects related to UD | ||
| SUD: Surface Syntactic Universal Dependencies ▪ Deep Universal Dependencies ▪ Universal PropBank ▪ CorefUD: Coreference in Universal Dependencies ▪ UNER: Universal Named Entity Recognition ▪ UMR: Uniform Meaning Representation ▪ UniMorph ▪ UDMorph ▪ UDer: Universal Derivations ▪ PARSEME: Multiword expressions ▪ UniDive COST Action ▪ UCxn: Universal Constructions ▪ UD on Hugging Face | ||
📖 Overview Publications
- Linguistic framework
- Marie-Catherine de Marneffe, Christopher Manning, Joakim Nivre, and Daniel Zeman (2021). Universal Dependencies. Computational Linguistics 47(2): 255–308.
- Treebank data
- Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Jan Hajič, Christopher Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman (2020). Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection. Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020), pp. 4034–4043, Marseille, France.
Current UD Languages
Information about language families (and genera for families with multiple branches) is mostly taken from WALS Online (IE = Indo-European).
 Abaza
1
<1K
Northwest Caucasian
Abaza
1
<1K
Northwest Caucasian
 Abkhaz
1
13K
Northwest Caucasian
Abkhaz
1
13K
Northwest Caucasian
 Afrikaans
1
49K
IE, Germanic
Afrikaans
1
49K
IE, Germanic
 Akkadian
2
25K
Afro-Asiatic, Semitic
Akkadian
2
25K
Afro-Asiatic, Semitic
Akkadian treebanks


Language documentation
See the language documentation page. Akuntsu
1
1K
Tupian, Tupari
Akuntsu
1
1K
Tupian, Tupari
 Albanian
2
4K
IE, Albanian
Albanian
2
4K
IE, Albanian
Albanian treebanks

Language documentation
See the language documentation page. Alemannic
2
21K
IE, Germanic
Alemannic
2
21K
IE, Germanic
Alemannic treebanks

Language documentation
See the language documentation page. Amharic
1
10K
Afro-Asiatic, Semitic
Amharic
1
10K
Afro-Asiatic, Semitic
 Ancient Greek
3
456K
IE, Greek
Ancient Greek
3
456K
IE, Greek
Ancient Greek treebanks


Language documentation
See the language documentation page. Ancient Hebrew
1
145K
Afro-Asiatic, Semitic
Ancient Hebrew
1
145K
Afro-Asiatic, Semitic
 Apurina
1
1K
Arawakan, Purus
Apurina
1
1K
Arawakan, Purus
 Arabic
3
1,042K
Afro-Asiatic, Semitic
Arabic
3
1,042K
Afro-Asiatic, Semitic
Arabic treebanks

Language documentation
See the language documentation page. Armenian
2
150K
IE, Armenian
Armenian
2
150K
IE, Armenian
Armenian treebanks

Language documentation
See the language documentation page. Assamese
1
<1K
IE, Indic
Assamese
1
<1K
IE, Indic
 Assyrian
1
<1K
Afro-Asiatic, Semitic
Assyrian
1
<1K
Afro-Asiatic, Semitic
 Azerbaijani
1
<1K
Turkic, Southwestern
Azerbaijani
1
<1K
Turkic, Southwestern
 Bambara
1
13K
Mande
Bambara
1
13K
Mande
 Basque
1
121K
Basque
Basque
1
121K
Basque
 Bavarian
1
15K
IE, Germanic
Bavarian
1
15K
IE, Germanic
 Beja
1
11K
Afro-Asiatic, Cushitic
Beja
1
11K
Afro-Asiatic, Cushitic
 Belarusian
1
305K
IE, Slavic
Belarusian
1
305K
IE, Slavic
 Bengali
1
<1K
IE, Indic
Bhojpuri
1
6K
IE, Indic
Bengali
1
<1K
IE, Indic
Bhojpuri
1
6K
IE, Indic
 Bokota
1
2K
Chibchan, Guaymiic
Bororo
1
160K
Bororoan
Bokota
1
2K
Chibchan, Guaymiic
Bororo
1
160K
Bororoan
 Brahui
1
<1K
Dravidian
Brahui
1
<1K
Dravidian
 Breton
1
10K
IE, Celtic
Breton
1
10K
IE, Celtic
 Bulgarian
1
156K
IE, Slavic
Bulgarian
1
156K
IE, Slavic
 Buryat
1
10K
Mongolic
Buryat
1
10K
Mongolic
 Cantonese
1
13K
Sino-Tibetan, Chinese
Cantonese
1
13K
Sino-Tibetan, Chinese
 Cappadocian
2
4K
IE, Greek
Cappadocian
2
4K
IE, Greek
Cappadocian treebanks

Language documentation
See the language documentation page. Catalan
1
547K
IE, Romance
Catalan
1
547K
IE, Romance
 Cebuano
1
1K
Austronesian, Greater Central Philippine
Cebuano
1
1K
Austronesian, Greater Central Philippine
 Central Kurdish
1
<1K
IE, Iranian
Central Kurdish
1
<1K
IE, Iranian
 Chinese
7
309K
Sino-Tibetan, Chinese
Chinese
7
309K
Sino-Tibetan, Chinese
Chinese treebanks
Language documentation
See the language documentation page. Chintang
1
14K
Sino-Tibetan, Himalayish
Chintang
1
14K
Sino-Tibetan, Himalayish
 Chukchi
1
6K
Chukotko-Kamchatkan
Chukchi
1
6K
Chukotko-Kamchatkan
 Classical Armenian
1
99K
IE, Armenian
Classical Armenian
1
99K
IE, Armenian
 Classical Chinese
2
433K
Sino-Tibetan, Chinese
Classical Chinese
2
433K
Sino-Tibetan, Chinese
Classical Chinese treebanks
Language documentation
See the language documentation page. Coptic
2
91K
Afro-Asiatic, Egyptian
Coptic
2
91K
Afro-Asiatic, Egyptian
Coptic treebanks


Language documentation
See the language documentation page. Croatian
1
199K
IE, Slavic
Croatian
1
199K
IE, Slavic
 Czech
6
4,162K
IE, Slavic
Czech
6
4,162K
IE, Slavic
Czech treebanks

Language documentation
See the language documentation page. Danish
1
100K
IE, Germanic
Danish
1
100K
IE, Germanic
 Dutch
2
505K
IE, Germanic
Dutch
2
505K
IE, Germanic
Dutch treebanks
Language documentation
See the language documentation page. Egyptian
1
34K
Afro-Asiatic, Egyptian
Egyptian
1
34K
Afro-Asiatic, Egyptian
 English
13
1,126K
IE, Germanic
English
13
1,126K
IE, Germanic
English treebanks
Language documentation
See the language documentation page. Erzya
1
20K
Uralic, Mordvin
Erzya
1
20K
Uralic, Mordvin
 Esperanto
2
3K
Constructed
Esperanto
2
3K
Constructed
Esperanto treebanks
Language documentation
See the language documentation page. Estonian
2
528K
Uralic, Finnic
Estonian
2
528K
Uralic, Finnic
Estonian treebanks
Language documentation
See the language documentation page. Faroese
2
50K
IE, Germanic
Faroese
2
50K
IE, Germanic
Faroese treebanks
Language documentation
See the language documentation page. Finnish
4
397K
Uralic, Finnic
Finnish
4
397K
Uralic, Finnic
Finnish treebanks
Language documentation
See the language documentation page. French
9
708K
IE, Romance
French
9
708K
IE, Romance
French treebanks

Language documentation
See the language documentation page. Frisian Dutch
1
3K
Code switching
Frisian Dutch
1
3K
Code switching
 Galician
3
188K
IE, Romance
Galician
3
188K
IE, Romance
Galician treebanks
Language documentation
See the language documentation page. Georgian
2
83K
Kartvelian
Georgian
2
83K
Kartvelian
Georgian treebanks
Language documentation
See the language documentation page. German
4
3,810K
IE, Germanic
German
4
3,810K
IE, Germanic
German treebanks
Language documentation
See the language documentation page.
Gheg
1
15K
IE, Albanian
 Gorontalo
1
<1K
Austronesian, Greater Central Philippine
Gorontalo
1
<1K
Austronesian, Greater Central Philippine
 Gothic
1
55K
IE, Germanic
Greek
6
110K
IE, Greek
Gothic
1
55K
IE, Germanic
Greek
6
110K
IE, Greek
Greek treebanks
Language documentation
See the language documentation page.
Guajajara
1
9K
Tupian, Maweti-Guarani
 Guarani
1
<1K
Tupian, Maweti-Guarani
Gujarati
1
1K
IE, Indic
Guarani
1
<1K
Tupian, Maweti-Guarani
Gujarati
1
1K
IE, Indic
 Gwichin
1
1K
Na-Dene
Gwichin
1
1K
Na-Dene
 Haitian Creole
2
75K
Creole
Haitian Creole
2
75K
Creole
Haitian Creole treebanks
Language documentation
See the language documentation page. Hausa
4
53K
Afro-Asiatic, West Chadic
Hausa
4
53K
Afro-Asiatic, West Chadic
Hausa treebanks
Language documentation
See the language documentation page.
Hebrew
4
376K
Afro-Asiatic, Semitic
Hebrew treebanks
Language documentation
See the language documentation page. Highland P. Nahuatl
1
10K
Uto-Aztecan
Highland P. Nahuatl
1
10K
Uto-Aztecan
Highland Puebla Nahuatl treebanks
Language documentation
See the language documentation page.
Hindi
2
375K
IE, Indic
Hindi treebanks
Language documentation
See the language documentation page. Hittite
1
1K
IE, Anatolian
Hittite
1
1K
IE, Anatolian
 Hungarian
1
42K
Uralic, Ugric
Hungarian
1
42K
Uralic, Ugric
 Icelandic
4
1,183K
IE, Germanic
Icelandic
4
1,183K
IE, Germanic
Icelandic treebanks
Language documentation
See the language documentation page. Ika
1
5K
Chibchan, Arhuacic
Indonesian
3
169K
Austronesian, Malayo-Sumbawan
Ika
1
5K
Chibchan, Arhuacic
Indonesian
3
169K
Austronesian, Malayo-Sumbawan
Indonesian treebanks
Language documentation
See the language documentation page. Irish
3
168K
IE, Celtic
Irish
3
168K
IE, Celtic
Irish treebanks
Language documentation
See the language documentation page. Italian
11
1,020K
IE, Romance
Italian
11
1,020K
IE, Romance
Italian treebanks
Language documentation
See the language documentation page. Japanese
6
2,645K
Japanese
Japanese
6
2,645K
Japanese
Japanese treebanks

Language documentation
See the language documentation page.
Javanese
1
14K
Austronesian, Javanese
Kaapor
1
<1K
Tupian, Maweti-Guarani
Kadiweu
1
<1K
Guaicuruan
Kangri
1
2K
IE, Indic
 Karelian
1
3K
Uralic, Finnic
Karo
1
2K
Tupian, Ramarama
Karelian
1
3K
Uralic, Finnic
Karo
1
2K
Tupian, Ramarama
 Kazakh
1
10K
Turkic, Northwestern
Kazakh
1
10K
Turkic, Northwestern
 Khoekhoe
1
29K
Khoe-Kwadi
Khoekhoe
1
29K
Khoe-Kwadi
 Kiche
1
10K
Mayan
Kiche
1
10K
Mayan
 Komi Permyak
1
1K
Uralic, Permic
Komi Permyak
1
1K
Uralic, Permic
 Komi Zyrian
2
10K
Uralic, Permic
Komi Zyrian
2
10K
Uralic, Permic
Komi Zyrian treebanks
Language documentation
See the language documentation page. Korean
5
615K
Korean
Korean
5
615K
Korean
Korean treebanks
Language documentation
See the language documentation page. Kyrgyz
2
25K
Turkic, Northwestern
Kyrgyz
2
25K
Turkic, Northwestern
Kyrgyz treebanks
Language documentation
See the language documentation page. Latgalian
1
<1K
IE, Baltic
Latgalian
1
<1K
IE, Baltic
 Latin
6
1,012K
IE, Italic
Latin
6
1,012K
IE, Italic
Latin treebanks
Language documentation
See the language documentation page. Latvian
2
330K
IE, Baltic
Latvian
2
330K
IE, Baltic
Latvian treebanks
Language documentation
See the language documentation page. Ligurian
1
6K
IE, Romance
Ligurian
1
6K
IE, Romance
 Lithuanian
2
75K
IE, Baltic
Lithuanian
2
75K
IE, Baltic
Lithuanian treebanks
Language documentation
See the language documentation page.
Livvi
1
1K
Uralic, Finnic
 Low Saxon
1
22K
IE, Germanic
Low Saxon
1
22K
IE, Germanic
 Luxembourgish
1
<1K
IE, Germanic
Luxembourgish
1
<1K
IE, Germanic
 Macedonian
1
1K
IE, Slavic
Madi
1
<1K
Arawan
Macedonian
1
1K
IE, Slavic
Madi
1
<1K
Arawan
 Maghrebi Arabic French
1
19K
Code switching
Maghrebi Arabic French
1
19K
Code switching
Maghrebi Arabic French treebanks
Language documentation
See the language documentation page.
Makurap
1
<1K
Tupian, Tupari
Malayalam
1
2K
Dravidian
 Maltese
1
44K
Afro-Asiatic, Semitic
Maltese
1
44K
Afro-Asiatic, Semitic
 Manx
1
20K
IE, Celtic
Marathi
2
122K
IE, Indic
Manx
1
20K
IE, Celtic
Marathi
2
122K
IE, Indic
Marathi treebanks
Language documentation
See the language documentation page.
Mbya Guarani
1
1K
Tupian, Maweti-Guarani
Mbya Guarani treebanks
Language documentation
See the language documentation page. Middle Armenian
1
1K
IE, Armenian
Middle Armenian
1
1K
IE, Armenian
 Middle French
2
126K
IE, Romance
Middle French
2
126K
IE, Romance
Middle French treebanks
Language documentation
See the language documentation page. Moksha
1
4K
Uralic, Mordvin
Munduruku
1
1K
Tupian, Munduruku
Naga
1
3K
Sino-Tibetan, Tangkhul-Maring
Naija
1
140K
Creole
Moksha
1
4K
Uralic, Mordvin
Munduruku
1
1K
Tupian, Munduruku
Naga
1
3K
Sino-Tibetan, Tangkhul-Maring
Naija
1
140K
Creole
 Neapolitan
1
<1K
IE, Romance
Neapolitan
1
<1K
IE, Romance
 Nenets
1
1K
Uralic, Samoyedic
Nepali
1
<1K
IE, Indic
Nheengatu
1
26K
Tupian, Maweti-Guarani
Nenets
1
1K
Uralic, Samoyedic
Nepali
1
<1K
IE, Indic
Nheengatu
1
26K
Tupian, Maweti-Guarani
 North Sami
1
26K
Uralic, Sami
Northern Kurdish
1
10K
IE, Iranian
North Sami
1
26K
Uralic, Sami
Northern Kurdish
1
10K
IE, Iranian
 Northwest Gbaya
1
2K
Niger-Congo, Gbaya-Manza-Ngbaka
Northwest Gbaya
1
2K
Niger-Congo, Gbaya-Manza-Ngbaka
 Norwegian
2
611K
IE, Germanic
Norwegian
2
611K
IE, Germanic
Norwegian treebanks
Language documentation
See the language documentation page. Occitan
1
25K
IE, Romance
Odia
1
5K
IE, Indic
Occitan
1
25K
IE, Romance
Odia
1
5K
IE, Indic
 Old Church Slavonic
1
198K
IE, Slavic
Old Church Slavonic
1
198K
IE, Slavic
Old Church Slavonic treebanks
Language documentation
See the language documentation page. Old East Slavic
4
580K
IE, Slavic
Old East Slavic
4
580K
IE, Slavic
Old East Slavic treebanks
Language documentation
See the language documentation page. Old English
1
<1K
IE, Germanic
Old French
2
255K
IE, Romance
Old English
1
<1K
IE, Germanic
Old French
2
255K
IE, Romance
Old French treebanks
Language documentation
See the language documentation page.
Old Georgian
1
6K
Kartvelian
 Old Irish
2
<1K
IE, Celtic
Old Irish
2
<1K
IE, Celtic
Old Irish treebanks
Language documentation
See the language documentation page.
Old Occitan
1
52K
IE, Romance
 Old Turkish
1
<1K
Turkic, Northeastern
Old Turkish
1
<1K
Turkic, Northeastern
 Ottoman Turkish
3
31K
Turkic, Southwestern
Ottoman Turkish
3
31K
Turkic, Southwestern
Ottoman Turkish treebanks
Language documentation
See the language documentation page. Pashto
2
6K
IE, Iranian
Pashto
2
6K
IE, Iranian
Pashto treebanks
Language documentation
See the language documentation page.
Paumari
1
<1K
Arawan
 Persian
2
654K
IE, Iranian
Persian
2
654K
IE, Iranian
Persian treebanks
Language documentation
See the language documentation page. Pesh
1
4K
Chibchan, Pesh
Phrygian
1
1K
IE, Greek
Pesh
1
4K
Chibchan, Pesh
Phrygian
1
1K
IE, Greek
 Polish
4
546K
IE, Slavic
Polish
4
546K
IE, Slavic
Polish treebanks
Language documentation
See the language documentation page. Pomak
1
34K
IE, Slavic
Pomak
1
34K
IE, Slavic
 Portuguese
7
1,545K
IE, Romance
Portuguese
7
1,545K
IE, Romance
Portuguese treebanks

Language documentation
See the language documentation page.
Punjabi
2
3K
IE, Indic
Punjabi treebanks
Language documentation
See the language documentation page. Romanian
6
942K
IE, Romance
Romanian
6
942K
IE, Romance
Romanian treebanks
Language documentation
See the language documentation page. Russian
5
3,455K
IE, Slavic
Russian
5
3,455K
IE, Slavic
Russian treebanks
Language documentation
See the language documentation page. Ruuli
1
6K
Niger-Congo, Bantoid
Sanskrit
2
208K
IE, Indic
Ruuli
1
6K
Niger-Congo, Bantoid
Sanskrit
2
208K
IE, Indic
Sanskrit treebanks
Language documentation
See the language documentation page. Scottish Gaelic
1
90K
IE, Celtic
Scottish Gaelic
1
90K
IE, Celtic
 Serbian
1
97K
IE, Slavic
Shanghainese
1
8K
Sino-Tibetan, Chinese
Serbian
1
97K
IE, Slavic
Shanghainese
1
8K
Sino-Tibetan, Chinese
 Sicilian
1
11K
IE, Romance
Sindhi
1
95K
IE, Indic
Sicilian
1
11K
IE, Romance
Sindhi
1
95K
IE, Indic
 Sinhala
2
1K
IE, Indic
Sinhala
2
1K
IE, Indic
Sinhala treebanks
Language documentation
See the language documentation page.
Skolt Sami
1
3K
Uralic, Sami
 Slovak
1
106K
IE, Slavic
Slovak
1
106K
IE, Slavic
 Slovenian
2
365K
IE, Slavic
Slovenian
2
365K
IE, Slavic
Slovenian treebanks
Language documentation
See the language documentation page. South Levantine Arabic
1
<1K
Afro-Asiatic, Semitic
South Levantine Arabic
1
<1K
Afro-Asiatic, Semitic
South Levantine Arabic treebanks
Language documentation
See the language documentation page.
Southern Kurdish
1
1K
IE, Iranian
 Spanish
4
1,022K
IE, Romance
Spanish
4
1,022K
IE, Romance
Spanish treebanks
Language documentation
See the language documentation page.
Spanish Sign Language
1
1K
Sign Language
 Swedish
5
229K
IE, Germanic
Swedish
5
229K
IE, Germanic
Swedish treebanks
Language documentation
See the language documentation page.
Swedish Sign Language
1
1K
Sign Language
Tagalog
2
1K
Austronesian, Greater Central Philippine
Tagalog treebanks
Language documentation
See the language documentation page.
Tamil
2
12K
Dravidian
Tamil treebanks
Language documentation
See the language documentation page. Tatar
1
2K
Turkic, Northwestern
Teko
1
2K
Tupian, Maweti-Guarani
Telugu
1
6K
Dravidian
Telugu English
1
<1K
Code switching
Tatar
1
2K
Turkic, Northwestern
Teko
1
2K
Tupian, Maweti-Guarani
Telugu
1
6K
Dravidian
Telugu English
1
<1K
Code switching
 Thai
2
99K
Tai-Kadai
Thai
2
99K
Tai-Kadai
Thai treebanks
Language documentation
See the language documentation page. Tswana
1
<1K
Niger-Congo, Bantoid
Tupinamba
1
4K
Tupian, Maweti-Guarani
Turkish
10
735K
Turkic, Southwestern
Tswana
1
<1K
Niger-Congo, Bantoid
Tupinamba
1
4K
Tupian, Maweti-Guarani
Turkish
10
735K
Turkic, Southwestern
Turkish treebanks
Language documentation
See the language documentation page.
Turkish English
1
<1K
Code switching
Turkish German
1
37K
Code switching
 Ukrainian
2
231K
IE, Slavic
Ukrainian
2
231K
IE, Slavic
Ukrainian treebanks
Language documentation
See the language documentation page. Umbrian
1
1K
IE, Italic
Umbrian
1
1K
IE, Italic
 Upper Sorbian
1
11K
IE, Slavic
Urdu
1
138K
IE, Indic
Uyghur
1
40K
Turkic, Southeastern
Upper Sorbian
1
11K
IE, Slavic
Urdu
1
138K
IE, Indic
Uyghur
1
40K
Turkic, Southeastern
 Uzbek
3
14K
Turkic, Southeastern
Uzbek
3
14K
Turkic, Southeastern
Uzbek treebanks
Language documentation
See the language documentation page. Veps
1
1K
Uralic, Finnic
Veps
1
1K
Uralic, Finnic
 Vietnamese
2
59K
Austro-Asiatic, Viet-Muong
Vietnamese
2
59K
Austro-Asiatic, Viet-Muong
Vietnamese treebanks
Language documentation
See the language documentation page. Warlpiri
1
<1K
Pama-Nyungan, Western
Warlpiri
1
<1K
Pama-Nyungan, Western
 Welsh
1
54K
IE, Celtic
Western Armenian
1
122K
IE, Armenian
Western S.P. Nahuatl
1
19K
Uto-Aztecan
Welsh
1
54K
IE, Celtic
Western Armenian
1
122K
IE, Armenian
Western S.P. Nahuatl
1
19K
Uto-Aztecan
Western Sierra Puebla Nahuatl treebanks
Language documentation
See the language documentation page. Wolof
1
44K
Niger-Congo, Northern Atlantic
Xavante
1
2K
Macro-Je
Xibe
1
15K
Tungusic
Wolof
1
44K
Niger-Congo, Northern Atlantic
Xavante
1
2K
Macro-Je
Xibe
1
15K
Tungusic
 Yakut
1
1K
Turkic, Northeastern
Yakut
1
1K
Turkic, Northeastern
 Yiddish
1
28K
IE, Germanic
Yoruba
1
8K
Niger-Congo, Defoid
Yupik
1
2K
Eskimo-Aleut
Zaar
1
20K
Afro-Asiatic, West Chadic
Zazaki
1
1K
IE, Iranian
Yiddish
1
28K
IE, Germanic
Yoruba
1
8K
Niger-Congo, Defoid
Yupik
1
2K
Eskimo-Aleut
Zaar
1
20K
Afro-Asiatic, West Chadic
Zazaki
1
1K
IE, Iranian
Disclaimer: Our use of flags to symbolise languages is only intended as a visual enhancement of the website and should not be interpreted as a political statement in any way.
Possible Future Extensions
People have expressed interest in providing annotated data for the following languages but no valid data has been provided so far.
Akkadian
1
117K
Afro-Asiatic, Semitic
Akkadian treebanks
Language documentation
See the language documentation page.
Amharic
3
<1K
Afro-Asiatic, Semitic
Amharic treebanks
Language documentation
See the language documentation page.
Apalai
1
<1K
Cariban
Apalai treebanks
Language documentation
The language hub documentation has not yet been created.
Balatipone
1
-
Bororoan
Balatipone treebanks
Language documentation
The language hub documentation has not yet been created.
Balochi
1
-
IE, Iranian
Bengali
3
2K
IE, Indic
Bengali treebanks
Language documentation
See the language documentation page. Central Romani
1
-
IE, Indic
Central Romani
1
-
IE, Indic
Central Romani treebanks
Language documentation
The language hub documentation has not yet been created. Chechen
1
-
Nakh-Daghestanian, Nakh
Chechen
1
-
Nakh-Daghestanian, Nakh
Chechen treebanks
Language documentation
The language hub documentation has not yet been created. Classical Nahuatl
1
-
Uto-Aztecan
Classical Nahuatl
1
-
Uto-Aztecan
 Corsican
1
-
IE, Romance
Corsican
1
-
IE, Romance
Corsican treebanks
Language documentation
The language hub documentation has not yet been created.
Cuicatec
1
-
Oto-Manguean
Cuicatec treebanks
Language documentation
The language hub documentation has not yet been created. Cusco Quechua
1
-
Quechuan
Cusco Quechua
1
-
Quechuan
Cusco Quechua treebanks
Language documentation
The language hub documentation has not yet been created.
Czech
1
-
IE, Slavic
Czech treebanks
Language documentation
See the language documentation page. Dargwa
1
-
Nakh-Daghestanian, Lak-Dargwa
Dargwa
1
-
Nakh-Daghestanian, Lak-Dargwa
Dargwa treebanks
Language documentation
The language hub documentation has not yet been created.
Enawene Nawe
1
-
Arawakan, Central Arawakan
Enawene Nawe treebanks
Language documentation
The language hub documentation has not yet been created.
French
1
-
IE, Romance
French treebanks
Language documentation
See the language documentation page.
French Sign Language
1
-
Sign Language
French Sign Language treebanks
Language documentation
The language hub documentation has not yet been created.
Frisian
1
51K
IE, Germanic
Frisian treebanks
Language documentation
The language hub documentation has not yet been created.
Gedeo
1
<1K
Afro-Asiatic, Cushitic
Gedeo treebanks
Language documentation
The language hub documentation has not yet been created.
Georgian
1
1K
Kartvelian
Georgian treebanks
Language documentation
See the language documentation page.
Gilaki
1
-
IE, Iranian
Gilaki treebanks
Language documentation
The language hub documentation has not yet been created.
Greek
2
-
IE, Greek
Greek treebanks
Language documentation
See the language documentation page.
Hiligaynon
1
<1K
Austronesian, Greater Central Philippine
Hiligaynon treebanks
Language documentation
The language hub documentation has not yet been created.
Hindi
1
4K
IE, Indic
Hindi treebanks
Language documentation
See the language documentation page.
Huave
1
-
Huavean
Huave treebanks
Language documentation
The language hub documentation has not yet been created.
Italian
1
-
IE, Romance
Italian treebanks
Language documentation
See the language documentation page.
Japanese
2
-
Japanese
Japanese treebanks
Language documentation
See the language documentation page.
Kabyle
1
23K
Afro-Asiatic, Berber
Kabyle treebanks
Language documentation
The language hub documentation has not yet been created.
Kiga
1
-
Niger-Congo, Bantoid
Kiga treebanks
Language documentation
The language hub documentation has not yet been created.
Komi
1
<1K
Uralic, Permic
Komi treebanks
Language documentation
The language hub documentation has not yet been created.
Kullvi
1
-
IE, Indic
Kullvi treebanks
Language documentation
The language hub documentation has not yet been created.
Ladino
1
-
IE, Romance
Ladino treebanks
Language documentation
The language hub documentation has not yet been created.
Laz
1
2K
Kartvelian
Laz treebanks
Language documentation
The language hub documentation has not yet been created.
Magahi
2
7K
IE, Indic
Magahi treebanks
Language documentation
The language hub documentation has not yet been created. Malagasy
1
-
Austronesian, Barito
Malagasy
1
-
Austronesian, Barito
Malagasy treebanks
Language documentation
The language hub documentation has not yet been created.
Mandyali
1
2K
IE, Indic
 Mansi
1
-
Uralic, Ugric
Mansi
1
-
Uralic, Ugric
Mansi treebanks
Language documentation
The language hub documentation has not yet been created.
Megrelian
1
-
Kartvelian
Middle Irish
2
<1K
IE, Celtic
Middle Irish treebanks
Language documentation
The language hub documentation has not yet been created. Middle Persian
1
-
IE, Iranian
Middle Persian
1
-
IE, Iranian
 Mongolian
1
-
Mongolic
Mongolian
1
-
Mongolic
Mongolian treebanks
Language documentation
The language hub documentation has not yet been created.
Nkore
1
-
Niger-Congo, Bantoid
Nkore treebanks
Language documentation
The language hub documentation has not yet been created.
Northern Kurdish
1
2K
IE, Iranian
Northern Luri
1
-
IE, Iranian
Occitan
1
-
IE, Romance
Old English
2
26K
IE, Germanic
Old Georgian
3
-
Kartvelian
Old Georgian treebanks
Language documentation
See the language documentation page.
Old Japanese
1
3K
Japanese
Old Occitan
1
-
IE, Romance
 Old Saxon
1
-
IE, Germanic
Palenquero
1
-
Creole
Old Saxon
1
-
IE, Germanic
Palenquero
1
-
Creole
Palenquero treebanks
Language documentation
The language hub documentation has not yet been created.
Pali
1
-
IE, Indic
Pali treebanks
Language documentation
The language hub documentation has not yet been created. Papiamento
2
-
Creole
Papiamento
2
-
Creole
Papiamento treebanks
Language documentation
The language hub documentation has not yet been created.
Peripheral Mongolian
1
-
Mongolic
Persian
3
-
IE, Iranian
Persian treebanks
Language documentation
See the language documentation page.
Pnar
1
-
Austro-Asiatic, Khasian
Pnar treebanks
Language documentation
The language hub documentation has not yet been created. Pontic
1
-
IE, Greek
Pontic
1
-
IE, Greek
Pontic treebanks
Language documentation
The language hub documentation has not yet been created.
Portuguese
2
101K
IE, Romance
Portuguese treebanks
Language documentation
See the language documentation page.
Prakrit
1
<1K
IE, Indic
Punjabi
1
6K
IE, Indic
Punjabi treebanks
Language documentation
See the language documentation page.
Puno Quechua
1
-
Quechuan
Puno Quechua treebanks
Language documentation
The language hub documentation has not yet been created. Sardinian
2
-
IE, Romance
Serbian
1
45K
IE, Slavic
Seri
1
-
Hokan, Seri
Sardinian
2
-
IE, Romance
Serbian
1
45K
IE, Slavic
Seri
1
-
Hokan, Seri
Seri treebanks
Language documentation
The language hub documentation has not yet been created.
Shipibo Konibo
1
-
Pano-Tacanan
Shipibo Konibo treebanks
Language documentation
The language hub documentation has not yet been created.
Sindhi
1
6K
IE, Indic
Spanish
1
<1K
IE, Romance
Spanish treebanks
Language documentation
See the language documentation page.
Spanish English
1
-
Code switching
Spanish English treebanks
Language documentation
The language hub documentation has not yet been created. Swahili
1
-
Niger-Congo, Bantoid
Swahili
1
-
Niger-Congo, Bantoid
Swahili treebanks
Language documentation
The language hub documentation has not yet been created.
Swedish
1
-
IE, Germanic
Swedish treebanks
Language documentation
See the language documentation page.
Tagabawa
1
<1K
Austronesian, Greater Central Philippine
Tagabawa treebanks
Language documentation
The language hub documentation has not yet been created.
Tagalog
1
340K
Austronesian, Greater Central Philippine
Tagalog treebanks
Language documentation
See the language documentation page. Tetun
1
-
Austronesian, Malayo-Polynesian
Tetun
1
-
Austronesian, Malayo-Polynesian
Tetun treebanks
Language documentation
The language hub documentation has not yet been created.
Thai
1
-
Tai-Kadai
Thai treebanks
Language documentation
See the language documentation page. Tigrinya
1
-
Afro-Asiatic, Semitic
Tigrinya
1
-
Afro-Asiatic, Semitic
Tigrinya treebanks
Language documentation
The language hub documentation has not yet been created. Tunisian Arabic
1
-
Afro-Asiatic, Semitic
Tunisian Arabic
1
-
Afro-Asiatic, Semitic
Tunisian Arabic treebanks
Language documentation
The language hub documentation has not yet been created.
Turkish
1
142K
Turkic, Southwestern
Turkish treebanks
Language documentation
See the language documentation page. Turkmen
1
47K
Turkic, Southwestern
Turkmen
1
47K
Turkic, Southwestern
Turkmen treebanks
Language documentation
The language hub documentation has not yet been created. Tuwari
1
-
Sepik
Tuwari
1
-
Sepik
Tuwari treebanks
Language documentation
The language hub documentation has not yet been created.
Uspanteko
1
13K
Mayan
Uspanteko treebanks
Language documentation
The language hub documentation has not yet been created.
Uyghur
1
-
Turkic, Southeastern
Disclaimer: Our use of flags to symbolise languages is only intended as a visual enhancement of the website and should not be interpreted as a political statement in any way.
Retired Treebanks
The following treebanks have been part of one or more UD releases in the past but they are no longer maintained and they have been excluded from the most recent release.
English
1
97K
IE, Germanic
English treebanks
Language documentation
See the language documentation page.
French
1
573K
IE, Romance
French treebanks
Language documentation
See the language documentation page.
Hindi English
1
26K
Code switching
Hindi English treebanks
Language documentation
The language hub documentation has not yet been created.
Japanese
2
204K
Japanese
Japanese treebanks
Language documentation
See the language documentation page.
Khunsari
1
<1K
IE, Iranian
Mbya Guarani
1
11K
Tupian, Maweti-Guarani
Mbya Guarani treebanks
Language documentation
See the language documentation page.
Nayini
1
<1K
IE, Iranian
Norwegian
1
55K
IE, Germanic
Norwegian treebanks
Language documentation
See the language documentation page.
Soi
1
<1K
IE, Iranian
Disclaimer: Our use of flags to symbolise languages is only intended as a visual enhancement of the website and should not be interpreted as a political statement in any way.
Diversity of the Latest Release
Languages per Family (Genus)
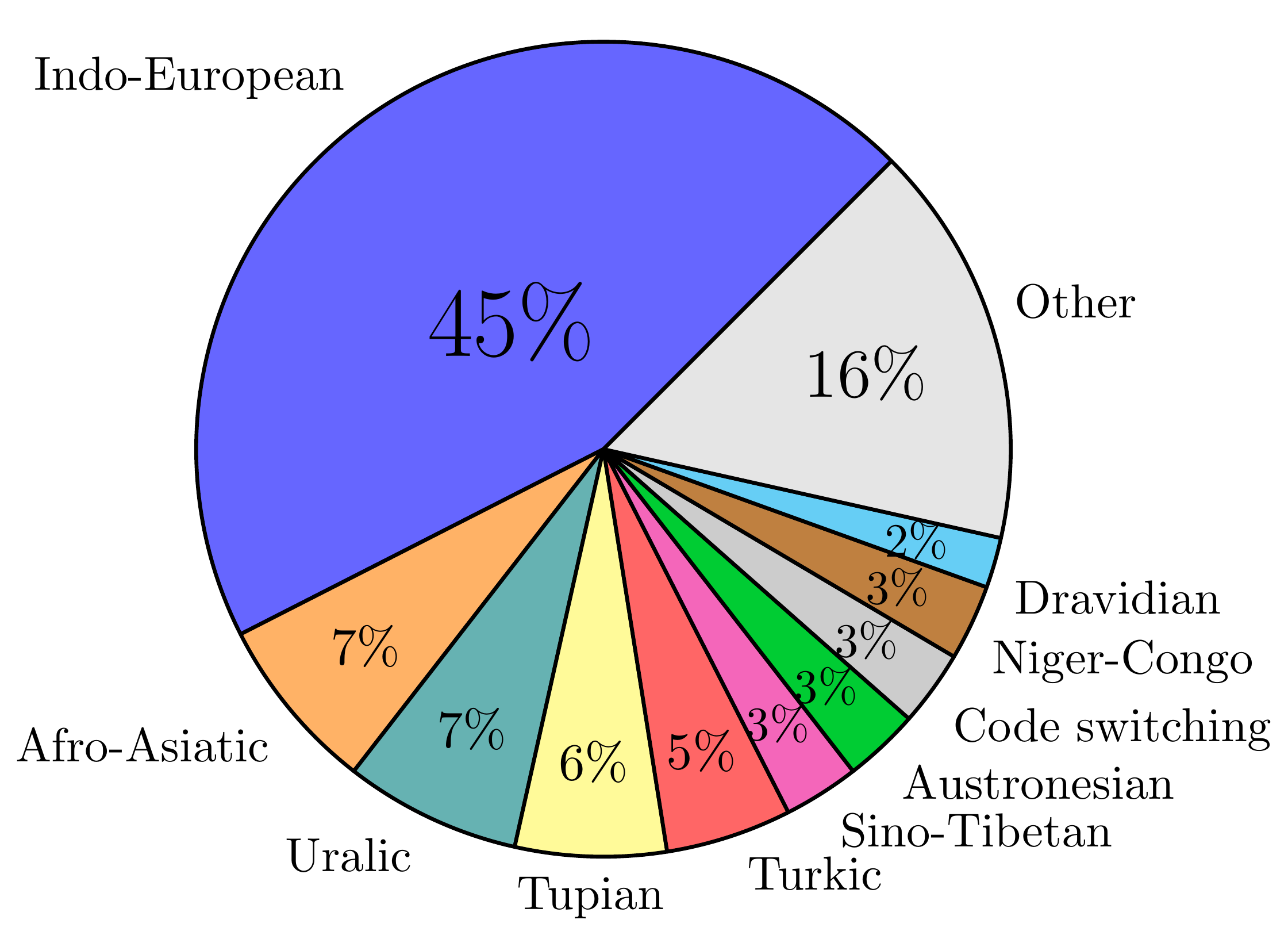
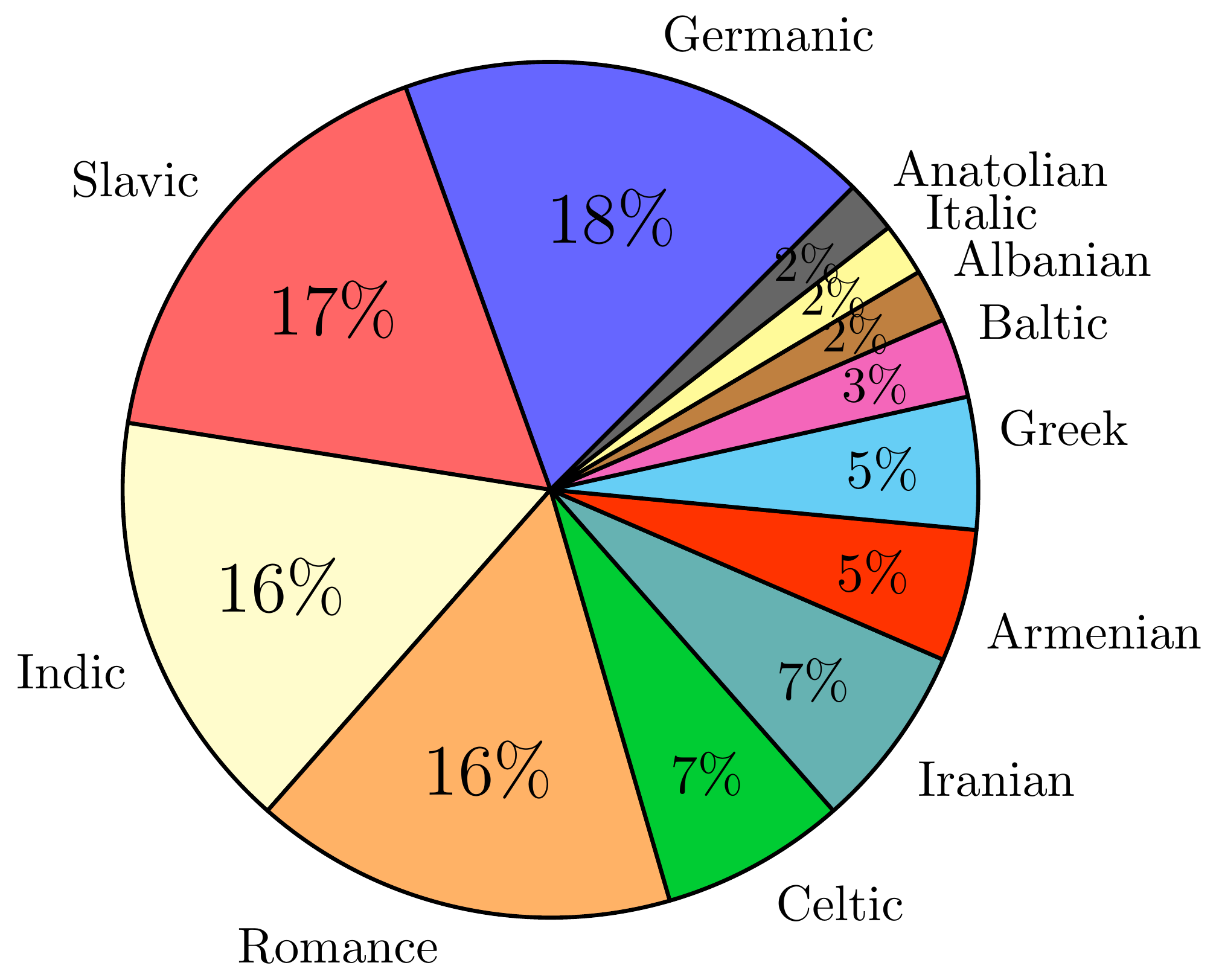
Words per Family (Genus)
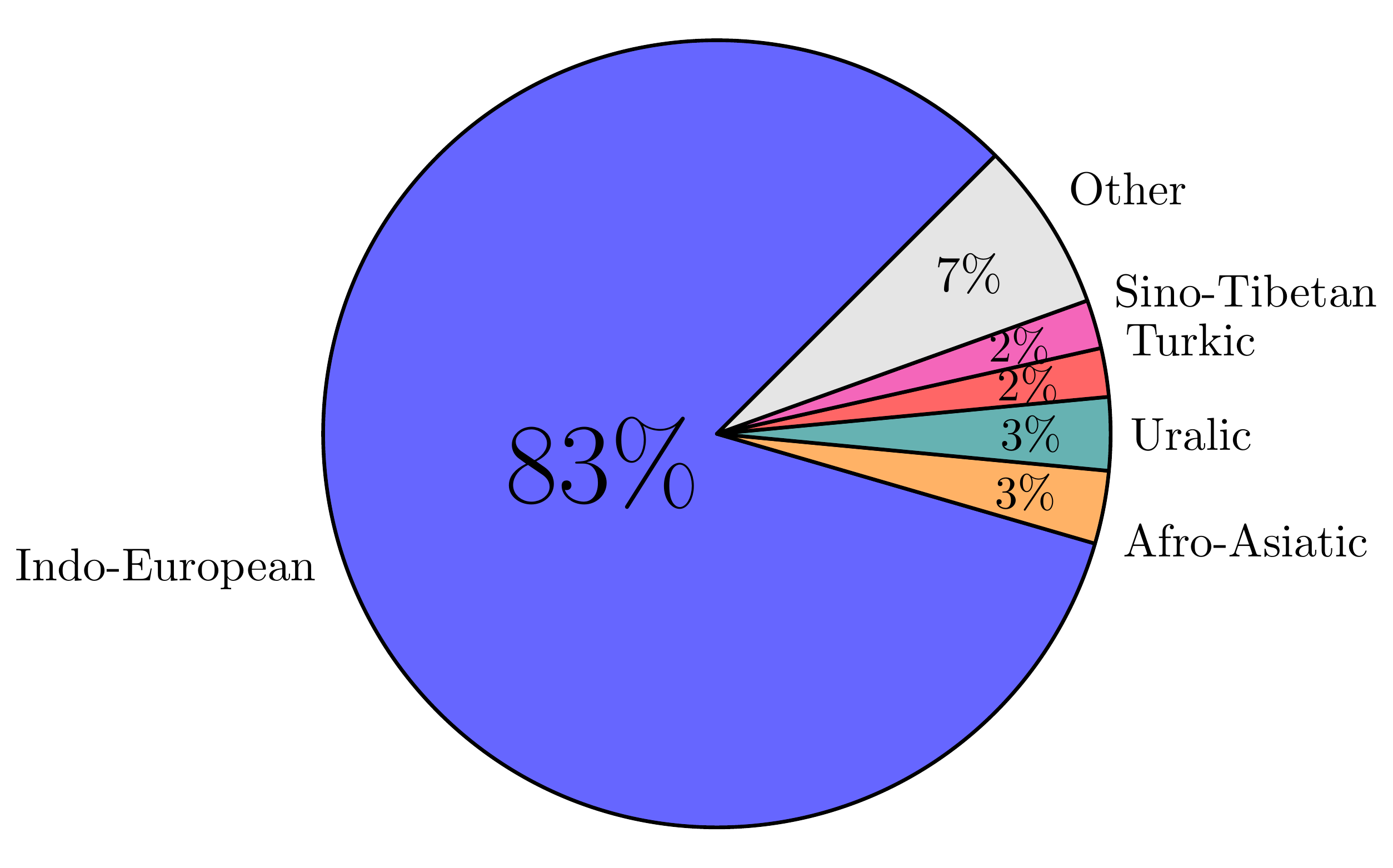
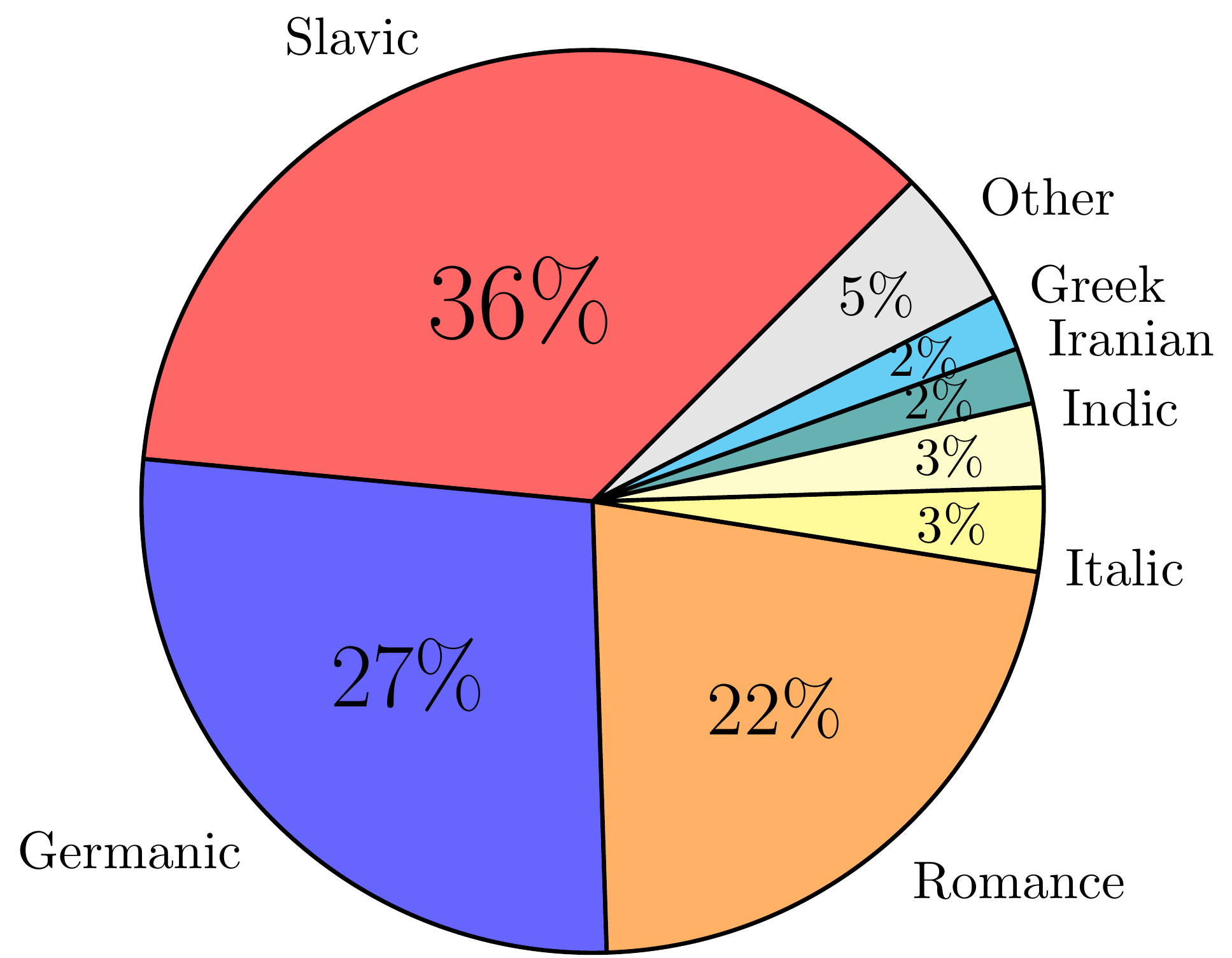
See also separate pages with a list of UD languages and a list of scripts used in UD treebanks.