Universal Dependencies tools
This page collects links to and minimal instructions for tools related to Universal Dependencies.
If you would like to have your tool added to this page, please submit a pull request for the corresponding Github page. You may also want to announce your tool in the UD mailing list.
Listing
- Tools maintained by the UD project
- Annotation statistics
- Consistency checking
- Data validation
- Format conversion
- Third-party tools
- Annotation tools
- Editor modes
- Processing tools
- Visualization tools
UD-maintained tools
The Universal Dependencies project maintains a number of core tools for working with UD data. These tools are available from https://github.com/universaldependencies/tools; see that repository directly for the list of scripts and their documentation (either in the README.md file or directly in the source code).
Among others, there are scripts for
- the official validation of UD files
- the official evaluation of parsing accuracy
- various statistics on UD files
- format conversion
Third-party tools
Annotation Tools
brat rapid annotation tool
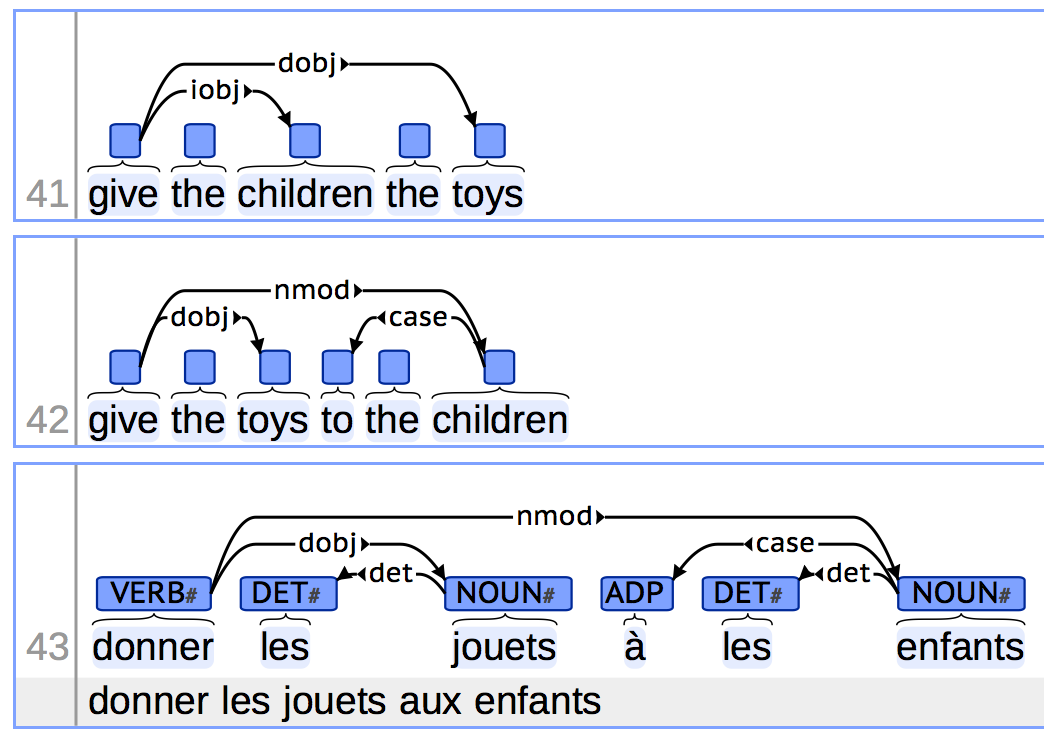 brat is a browser-based tool for text annotation. The brat visualization component is used in the UD documentation system and the tool comes with a custom configuration allowing it to be used for UD annotation .
brat is a browser-based tool for text annotation. The brat visualization component is used in the UD documentation system and the tool comes with a custom configuration allowing it to be used for UD annotation .
- Category: manual annotation tool
- Platform: any (browser-based)
- Implementation: Python (server), JavaScript (client)
- License: MIT (open source)
- Homepage: http://brat.nlplab.org/
- References: Stenetorp et al. (2012)
WebAnno
WebAnno is a general purpose web-based annotation tool for a wide range of linguistic annotations including various layers of morphological, syntactical, and semantic annotations. Additionaly, custom annotation layers can be defined, allowing WebAnno to be used also for non-linguistic annotation tasks. WebAnno targets annotation teams in which all annotators work independently from each other. The tool includes facilities for curating/merging the annotations from multiple annotators, calculating inter-annotator agreement, and project management. Additional features include a correction and automation mode as well as decent support for right-to-left languages.
Since version 3.0.0, WebAnno supports importing and exporting data in the CoNLL-U format. If the data contains sub-token annotations, then the text is obtained from the subtokens and the surface text is added as annotations. To control which column dependencies end up in, the flavor feature of the built-in dependency layer needs to be used. If the feature is set to enchanced, then it goes to the enhanced dependencies column, otherwise to the basic dependencies column. It is currently up to the annotator to ensure that the dependency trees are well-formed and representable in CoNLL-U, otherwise export to CoNLL-U may fail.
WebAnno 3.0.0 does not support the CoNLL-U 2.0 format at this time.
- Category: manual annotation tool
- Platform: client: any (browser-based), server: Java
- Implementation: Java (server), JavaScript (client)
- License: Apache License 2.0 (open source)
- Homepage: https://webanno.github.io/webanno/
- References: see WebAnno website
DgAnnotator
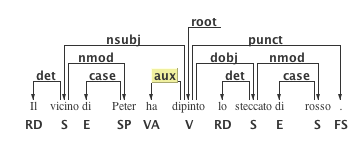 DgAnnotator (Dependency Graph Annotator) is a visual tool for annotating text with syntactic information, in particular creating a dependency tree. The tool reads and produces annotated documents in both XML, CoNLL-X and CoNLL-U tab separated format. Additional features: shows the differences, highlighted in red, between two different dependency trees on the same corpus; generates PNG snapshots of trees; performs PoS tagging and parsing connecting to a network service; panning and zooming.
DgAnnotator (Dependency Graph Annotator) is a visual tool for annotating text with syntactic information, in particular creating a dependency tree. The tool reads and produces annotated documents in both XML, CoNLL-X and CoNLL-U tab separated format. Additional features: shows the differences, highlighted in red, between two different dependency trees on the same corpus; generates PNG snapshots of trees; performs PoS tagging and parsing connecting to a network service; panning and zooming.
- Category: manual annotation tool
- Platform: Windows, Linux, OS X
- Implementation: Java
- License: GPL (open source)
- Homepage: http://medialab.di.unipi.it/Project/QA/Parser/DgAnnotator/
- References: Giuseppe Attardi
UD Annotatrix
UD Annotatrix is a browser-based offline + online annotation tool for dependency trees aimed at the UD community. It supports a number of features, including validation and two-level tokenisation.
- Category: manual annotation tool
- Platform: Any
- Implementation: Python, JavaScript
- License: GPL-3.0 (open source)
- Homepage: https://github.com/jonorthwash/ud-annotatrix
- References: Tyers, F. M., Sheyanova, M. and Washington, J. N. (2018) “UD Annotatrix: An annotation tool for Universal Dependencies”. Proceedings of the 16th Conference on Treebanks and Linguistic Theories
Tred
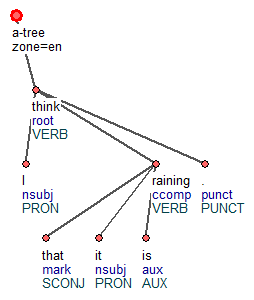 Tred (Tree Editor) is a graph visualization and manipulation program written in Perl. It was the main tool used to annotate the Prague treebanks. It supports macros (in Perl) to automate frequently repeated operations. There are extensions for various annotation layers such as MWEs or coreference. Since January 2018, there is also an extension for CoNLL-U files (including multi-word tokens and enhanced dependencies).
Tred (Tree Editor) is a graph visualization and manipulation program written in Perl. It was the main tool used to annotate the Prague treebanks. It supports macros (in Perl) to automate frequently repeated operations. There are extensions for various annotation layers such as MWEs or coreference. Since January 2018, there is also an extension for CoNLL-U files (including multi-word tokens and enhanced dependencies).
- Category: manual annotation tool
- Platform: Windows, Linux, OS X
- Implementation: Perl
- License: GPL (open source)
- Homepage: http://ufal.mff.cuni.cz/tred/
- References: Petr Pajas, Peter Fabian, Jan Štěpánek
ArboratorGrew
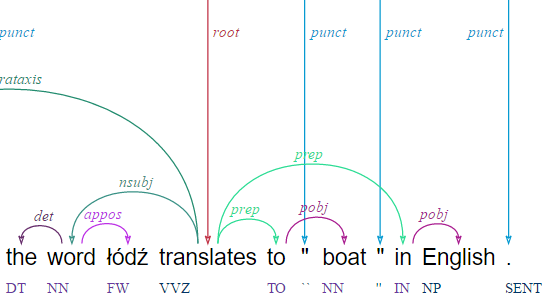 ** ArboratorGrew ** is a comprehensive, open-source, web-based tool designed for dependency treebank annotation. It supports a user-friendly drag-and-drop interface, along with social login features. Its project management capabilities allow for multiple users to collaborate simultaneously and compare trees for efficient and collaborative annotation efforts. The tool is equipped with a teacher mode and class-sourcing capabilities, making it suitable for both research and educational settings. It incorporates search and replace functions based on the Grew formalism, and an integrated neural bi-affine parser for quick bootstrapping. Additionally, it supports various annotation schemes, including UD, SUD, and custom-made schemes. https://arborator.grew.fr/
** ArboratorGrew ** is a comprehensive, open-source, web-based tool designed for dependency treebank annotation. It supports a user-friendly drag-and-drop interface, along with social login features. Its project management capabilities allow for multiple users to collaborate simultaneously and compare trees for efficient and collaborative annotation efforts. The tool is equipped with a teacher mode and class-sourcing capabilities, making it suitable for both research and educational settings. It incorporates search and replace functions based on the Grew formalism, and an integrated neural bi-affine parser for quick bootstrapping. Additionally, it supports various annotation schemes, including UD, SUD, and custom-made schemes. https://arborator.grew.fr/
- Category: manual annotation tool
- Platform: Any
- Implementation: Python, JavaScript
- License: AGPL-3.0 (open source)
- Homepage: https://arborator.grew.fr/
- References: Guibon, G., Courtin, M., Gerdes, K. and Guillaume, B., 2020, May. When collaborative treebank curation meets graph grammars. In LREC 2020-12th Language Resources and Evaluation Conference.
LightTag
LightTag is a general purpose text annotation tool which supports span annotations, classification as well as phrase-based and dependency-based relations. LightTag allows a drag-and-drop interface allowing annotators to easily drag individual tokens or sub-trees to construct their parse.
LightTag’s Universal Dependency Tool allows the user to paste an existing CoNLL-U file, visualize and correct the annotations. LightTag’s full featured text annotation tool supports managing teams of annotators, is fully hosted and available free for academic use.
- Category: manual annotation tool
- Platform: Web
- Implementation: Python, JavaScript
- License: See terms of use
- Homepage: https://lighttag.io/
- Contact: udep@lighttag.io
TrUDucer
TrUDucer is a tree rewriting system based on tree transducers. It transforms dependency trees in a top-down fashion, making sure that each resulting structure will still be a valid tree. Rules are written in a domain-specific language; for cases where the DSL is not powerfui enough, rules can be augmented by writing special-case predicates in groovy. It contains an interactive transformation viewer to debug rule applications and a search tool to find trees where a specific rule could be applicable. As of 2018, TrUDucer is under active development at Hamburg University.
An example rule file converting (large parts of) the Hamburg Dependency Treebank to UD is provided with TrUDucer. The Univerity of Zurich provides a rule file to convert the TIGER treebank to UD using TrUDucer.
- Category: automatic conversion tool
- Platform: Any
- Implementation: Java
- License: GPLv3 (open source)
- Homepage: http://nats.gitlab.io/truducer/
- References: Hennig, Felix and Köhn, Arne (2017), Dependency Tree Transformation with Tree Transducers. In: Proceedings of the NoDaLiDa 2017 Workshop on Universal Dependencies (UDW 2017). Gothenburg, 58–66.
- Contact: arne@chark.eu
ConlluEditor
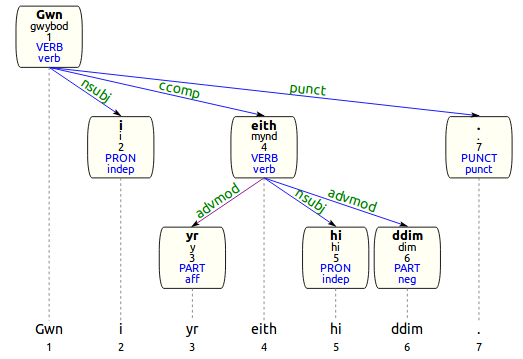 ConlluEditor is a tool which facilitates the editing of syntactic relations and morphological features of files in CoNLL-U format. It uses a Java-based server and a HTML/CSS/Javascript based front-end. The editor loads the CoNLL-U file and saves every change to disk (and performs a git commit if the file is under git version control).
It serves also as a graphical front-end to dependecy parsers (like the
UDPipe-Server).
ConlluEditor is a tool which facilitates the editing of syntactic relations and morphological features of files in CoNLL-U format. It uses a Java-based server and a HTML/CSS/Javascript based front-end. The editor loads the CoNLL-U file and saves every change to disk (and performs a git commit if the file is under git version control).
It serves also as a graphical front-end to dependecy parsers (like the
UDPipe-Server).
The editor provides the following functionalities:
- editing words (forms, lemmas, upos, xpos, features, enhanced dependencies)
- editing basic dependency relations and enhanced dependency relations
- autocompletion
- join/split words (to correct tokenization errors)
- join/split sentences (to correct tokenization errors)
- search (also sequences)
- undo/redo (partially)
- run validation scripts
- git support
- edit sentence metadata (sent_id, newdoc, newpar, translations, transliterations)
-
add initial transliteration (FORM -> MISC:Translit, LEMMA -> MISC:LTranslit)
- Category: manual annotation tool
- Platform: Any
- Implementation: Java, JavaScript, Python3
- License: BSD-3-Clause (open source)
- Homepage: https://github.com/Orange-OpenSource/conllueditor
-
References: Johannes Heinecke (2019): ConlluEditor: a fully graphical editor for Universal dependencies treebank files. In: Proceedings of the Universal Dependencies Workshop 2019. Paris. (Short demo video)
- Contact: johannes.heinecke@orange.com
Palmyra

Palmyra Palmyra is a configurable platform independent graphical dependency tree visualization and editing software. Palmyra has been designed with morphologically rich languages in mind, and thus has a number of features to support the complexities of these languages. These include supporting easy change of morphological tokenization through edits, additions, deletions and splits/merges of words. It can also be used to annotate a multitude of linguistic features. Palmyra uses an intuitive drag-and-drop metaphor for editing tree structures. Palmyra can be configured to be used with any dependency representation. A UD configuration file is provided in its github repo.
- Category: manual annotation tool
- Platform: Any
- Implementation: JavaScript
- License: open source
- Homepage: http://palmyra.camel-lab.com/
- References: Taji and Habash (2020): Dima Taji and Nizar Habash. 2020. PALMYRA 2.0: A Configurable Multilingual Platform Independent Tool for Morphology and Syntax Annotation. In Proceedings of Universal Dependencies Workshop (UDW) 2020..
- Contact: Nizar Habash (nizar.habash@nyu.edu)
BoAT
BoAT (Boğaziçi University Annotation Tool) is a collaborative annotation tool for Universal Dependencies treebanks. It supports sentence-by-sentence CoNLL-U annotation with dependency graph visualization, autocompletion, UD validation, advanced search, inter-annotator agreement, and multi-treebank/multi-annotator management. BoAT is available as both a web application and a desktop app (via Tauri), with the desktop app supporting offline annotation of local CoNLL-U files.
- Category: manual annotation tool
- Platform: any (browser-based); desktop app for Linux, macOS, Windows
- Implementation: Python/FastAPI (server), SvelteKit/TypeScript (client), Rust/Tauri (desktop)
- License: MIT (open source)
- Homepage: gitlab.com/furkan5204/boat
- References: Akkurt et al. (2022)
- Contact: Furkan Akkurt (furkan.akkurt@bogazici.edu.tr)
ConlluVisualiser
ConlluVisualiser is a tree visualizer and editor inspired by TrEd but developed directly for CoNLL-U.
- Category: manual annotation tool
- Platform: Microsoft Windows
- Implementation: C#
- Homepage: https://github.com/ufal/conllu-visualiser
- References: Storzerová (2019)
- Author: Tereza Storzerová
- Contact: Dan Zeman (zeman@ufal.mff.cuni.cz)
Editor modes
Emacs
conllu-mode is an Emacs mode for editing CoNLL-U files (syntax highlighting, column alignment, shortcuts for navigation, etc).
- Category: editor
- Platform: any OS that runs Emacs
- Implementation: Emacs Lisp
- License: GPL 3.0
- Homepage https://github.com/odanoburu/conllu-mode
Atom
This package provides syntax highlighting for CoNLL-U files in Atom.
- Category: editor
- Platform: any OS that runs Atom
- Implementation: –
- License: Apache 2.0
- Homepage https://atom.io/packages/language-conllu
Sublime Text
Syntax highlighting for CoNLL-U files on Sublime Text.
- Category: editor
- Platform: any OS that runs Sublime Text
- Implementation: –
- License: Apache 2.0
- Homepage https://github.com/stephsamson/CoNLL-U.tmLanguage/
Vim
Basic syntax highlighting and automatic syntax checking (through ALE or syntastic) for CONLL-U files.
- Category: editor
- Platform: any OS that runs Vim
- Implementation: vimscript
- License: GPL 3.0
- Homepage https://github.com/flammie/vim-conllu/
Processing tools
CL-CoNLLU
A Common Lisp library for various CoNLL-U-related operations. We have already functions for reading, writing, making queries, construct visualizations of sentences, compare trees etc.
- Category: library
- Platform: any OS that runs a Common Lisp implementation
- Implementation: Common Lisp
- License: Apache License
- Homepage: https://github.com/own-pt/cl-conllu/
- References: http://arademaker.github.io/bibliography/tilic-stil-2017.html
hs-conllu
A Haskel library for various CoNLL-U-related operations. So far, the basic functions for reading and writing. The plan is to port all other functions from the CL-CONLLU
- Category: library
- Platform: any OS that runs a Haskell compiler/interpreter
- Implementation: Haskell
- License: Apache License
- Homepage: https://hackage.haskell.org/package/hs-conllu
- References: see homepage
DepEdit
DepEdit is a simple, open source, configurable tool for manipulating dependency trees, written in Python (2/3). It can be run standalone from the commandline or imported as a module, and it is available on PyPI (pip install depedit). Main features:
- Identify target subtrees based on regex matching of token attributes, distance between tokens, and subgraph edges
- Change token attributes (incl. text, pos, morph, etc.)
- Use regex capturing groups in find/replace values (e.g. allows for collapsing captured prepositions into the deprel of the governing token)
- Connect different tokens in the tree by setting their head feature to one of the match objects
- Use external configuration files for different scenarios or define rules programmatically when used as a module
- No language or schema specific details are hardwired into the system - everything is defined in the configuration file
-
Can be used as a very rudimentary rule-based parser to pre-process data with easy dependencies before manual annotation (e.g. attach all articles to following nouns as
det) - Category: library
- Platform: Windows, Linux, OSX
- Implementation: Python 2/3
- License: Apache License 2.0 (open source)
- Homepage: https://corpling.uis.georgetown.edu/depedit/
- References: see website
DKPro Core CoNLL-U reader/writer
DKPro Core is collection of software components for natural language processing (NLP) based on the Apache UIMA framework. DKPro Core can be used to build workflows that automatically process text using a wide range of NLP tools from third parties that are all interoperable (Stanford CoreNLP, Apache OpenNLP, ClearNLP, mate-tools, etc etc.). It also supports a range of different data formats and can be used to convert between the different supported formats.
Starting with version 1.9.0, DKPro Core supports reading and writing the CoNLL-U format.
The latest CoNLL-U 2.0 format is not yet supported.
- Category: UIMA component
- Platform: Windows, Linux, OS X
- Implementation: Java
- License: Apache License 2.0 (open source)
- Homepage: https://dkpro.github.io/dkpro-core/
- References: see DKPro Core website
pyconll
pyconll is a minimal, entirely python, library for parsing and writing CoNLL-U files. pyconll allows users to easily parse out info from CoNLL-U corpora, or to perform and write corpus transformations. pyconll aims to provide a low-level interface over the CoNLL-U annotation scheme that is easy to understand and works with the current standard. Further, since it is written in python, there is no need to learn a new DSL or tool.
- Category: library
- Platform: Any OS with Python 3 implementation
- Implementation: Python 3
- License: MIT License
- Homepage: https://pyconll.github.io/
- Documentation: https://pyconll.readthedocs.io/en/latest/
conllu
conllu is a python library that parses a CoNLL-U string into a nested python dictionary.
It’s easily installable with “pip install conllu”, has good documentation and a big test suite that ensures working code, and is very customizable, which means it also works for custom formats that are similar to CoNLL-U. It works with both Python 2 and Python 3.
- Category: library
- Platform: Any OS with Python 2 or Python 3 implementation
- Implementation: Python 2 and Python 3
- License: MIT License
- Homepage: https://pypi.org/project/conllu/
- Documentation: https://github.com/EmilStenstrom/conllu/blob/master/README.md
Treex
Treex is a modular natural language processing framework. It reads and writes data in many formats (including CoNLL-U) and provides API for dependency tree manipulation. Many treebanks have been harmonized in HamleDT and then converted to UD using Treex.
- Category: treebank processing framework
- Platform: tested mainly on Linux
- Implementation: Perl
- License: Perl
- Homepage: http://ufal.mff.cuni.cz/treex
- References: Popel and Žabokrtský (2010)
UDPipe
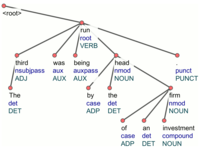 UDPipe is a trainable pipeline for tokenization, tagging, lemmatization and parsing of CoNLL-U files. UDPipe is language-agnostic and can be trained given only annotated data in CoNLL-U format. (Nevertheless, to train the tokenizer, either the
UDPipe is a trainable pipeline for tokenization, tagging, lemmatization and parsing of CoNLL-U files. UDPipe is language-agnostic and can be trained given only annotated data in CoNLL-U format. (Nevertheless, to train the tokenizer, either the SpaceAfter feature must be present, or at least some plain text must be available; also morphological analyzer and lemmatizer can be improved if morphological dictionary is provided.) Trained models are provided for nearly all UD treebanks. UDPipe is available as a binary, as a library for C++, Python, Perl, Java, C#, and as a web service.
- Category: trainable tokenizer, tagger, lemmatizer and parser
- Platform: Linux, Windows, OS X
- Implementation: C++; language bindings for Python, Perl, Java and C#
- License: MPL 2.0 (open source)
- Homepage: http://ufal.mff.cuni.cz/udpipe
- On-line service: http://lindat.mff.cuni.cz/services/udpipe/
- References: Milan Straka, Jan Hajič and Jana Straková 2016. UDPipe: Trainable Pipeline for Processing CoNLL-U Files Performing Tokenization, Morphological Analysis, POS Tagging and Parsing. LREC 2016, Portorož, Slovenia, May 2016.
UDAPI
- Category: libraries for various UD and CoNLL-U-related operations in several programming languages
- Implementation: Java, Perl, Python
- License: GPL, Perl
- Homepage: http://udapi.github.io/
UDon2
UDon2 is a library providing the possibility to manipulate Universal Dependencies trees. UDon2 is written in C++ with Python bindings via Boost.Python and is geared towards downstream NLP applications that require plenty of manipulations with individual dependency trees, including transforming UD trees to trees without labels on edges (as defined by Croce et. al. (2011)) to be used in ML algorithms. The package can perform these manipulations, as well as reading and writing to CoNLL-U files, efficiently (see benchmarks. UDon2 lacks command-line interface and thus is not recommended by the authors for working with treebanks.
- Category: library
- Implementation: C++ (with Python bindings)
- Platform: Linux and Windows (contributions for supporting OS X are welcome)
- License: MIT (starting from release 0.1b1)
- Homepage: https://github.com/udon2/udon2
- Documentation: https://udon2.github.io/
- References: Kalpakchi and Boye (2020)
ACoLi CoNLL Libraries
The ACoLi CoNLL Libraries provide advanced tools for processing, creating and manipulating CoNLL/TSV formats, including CoNLL-U and CoNLL-U Plus. In particular, this includes merging, transforming and querying CoNLL and other TSV (CSV) data:
- conversion between different CoNLL formats
- automated retokenization
- merging concurrent annotations (i.e., multiple annotations of the same token merged into a single row)
- machine-readable specs for more than 20 CoNLL and other TSV formats
- parsing CoNLL data into graphs and back
- rule-based transformation of CoNLL annotations, e.g., for annotation postprocessing, pre-annotation or rule-based parsing
- Linked Open Data publication of CoNLL corpora
- enrichment with external knowledge bases
- support for domain-specific extensions of the original tabular design of CoNLL formats, in particular for
- syntactic dependencies (resolving foreign keys/object properties),
- Semantic Role annotations (variable-sized tables),
- PTB phrase structure notation (parsed into directed acyclic graph),
- infused XML markup (also parsed into a directed acyclic graph),
- multi-layer annotations (multiple directed acyclic graphs over the same text)
None of these operations are limited to CoNLL-U, but CoNLL-U and CoNLL-U Plus are supported as input and output formats.
- Category: library, shell
- Platform: any OS that runs Java. Some shell scripts require Bash 4.0+ (MacOS users might need to upgrade the pre-installed Bash)
- Implementation: Java
- License: Apache License
- Homepage: https://github.com/acoli-repo/conll
- References: Chiarcos and Schenk (2018)
Visualization tools
Deptreeviz
Deptreeviz is a SVG visualization and editing component. It can be used as a swing component or to create SVGs from the command line. It supports drag-and-drop modifications of trees, including dependency label and selecting the correct lexical items. For the editing facilities, a matching backend needs to be programmed. Deptreeviz is used to convert the Hamburg Dependency Treebank to UD.
- Category: tree visualization (SVG graphics)
- Platform: Any
- Implementation: Java
- License: Apache License 2.0 (open source)
- Homepage: <https://gitlab.com/nats/deptreeviz
- References: Sven Zimmer, Arne Köhn
CoNLL-U viewer
A simple browser-based (JavaScript, i.e. client side) viewer of your CoNLL-U files. Open your file, see the tree, go to the next tree. Click on a node to see all its attributes. Save the tree as an SVG graphics if needed. There is no way of jumping directly to a tree, neither by tree number, nor by searching attribute values.
- Category: tree viewer
- Platform: any (browser-based)
- Implementation: JavaScript
- Credit: Milan Straka, Michal Sedlák
- Access here
CoNLL-U viewer at rug.nl
- Live site: http://www.let.rug.nl/kleiweg/conllu/
- Source code: Github
TüNDRA
TüNDRA (Tübingen aNnotated Data Retrieval Application) is a web application for searching in treebanks using a lightweight query language inspired by the widely used TIGERSearch application. It offers corpus linguists an interface for using corpora with complex annotation and syntactic links. Most of the treebanks available in TüNDRA are free and publicly available. To access all the treebanks a user has to have an account at a European institution of higher education (i.e. be a student or an employee). Any user may upload a CoNLL-U or a TCF file to browse/search it with the tool. A visualization is interactive (scaling, zooming, panning) and can be saved in multiple formats (e.g. to be later used for a publication). TüNDRA is a part of CLARIN-D project and is funded by the German Federal Ministry for Education and Research (BMBF).
- Category: tree viewer and search engine
- Platform: any (web application)
- Implementation: JavaScript, React (frontend), Java (backend)
- Credit: Department of General and Computational Linguistics at the University of Tübingen
- Access here
UDeasy
Udeasy is an application written in Python 3 whose main goal is to allow the user to easily query a treebank and extract patterns from a treebank in CoNLL-U format. To do this, users are prompted in a series of dialogs to enter relevant information about syntactic nodes, their properties, relationship, and positions. The functions to extract the occurrences from a treebank rely on the udapi Python package. The graphic interface is built using the GUI toolkit wxPython. Due to its ease of use it is a useful tool for the community of linguists who want to use a data-driven approach and for the students who approach dependency treebanks without almost any experience with queries.
- Category: tree viewer and search engine
- Platform: Linux, Windows, MacOS
- Implementation: Python
- Credit: Luca Brigada Villa
- Homepage here